C#でHTML文書からRSSのURLを取得するサンプル。
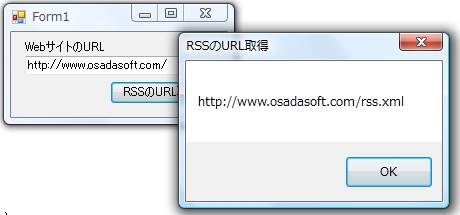
このサンプルでは以下の処理を行う。
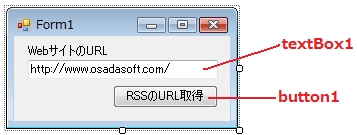
1.テキストボックスに対象となるHTML(WebサイトのURL)を指定。
2.[RSSのURL取得]ボタン押下。
3.取得したRSSが表示される。
GUIデザインでは、FormにtextBox1と、button1を貼り付ける。
ソースコードは以下の通り。
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Text;
using System.Windows.Forms;
namespace WindowsFormsApplication1
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
/*
HTML文書の中からRSSのURLを取得する。
RSSのURL情報は、HTML内に以下のような形式で保存されている。
<link type="application/rss+xml" title="RSS"
href="http://www.osadasoft.com/rss.xml" />
*/
WebBrowser webBrowser1 = new WebBrowser();
webBrowser1.Navigate(textBox1.Text);
while (!webBrowser1.IsBusy)
{
// 無限ループに陥らないようイベントを処理
Application.DoEvents();
}
// サイトによっては少し待たないと取得に失敗する
System.Threading.Thread.Sleep(500);
// HTML読み込み直後、最新の情報に更新させる
Application.DoEvents();
// HTML解析
HtmlDocument htmlDoc = webBrowser1.Document;
HtmlElementCollection elLinkCol =
htmlDoc.GetElementsByTagName("link");
// <link>タグを1つ1つ調べる
bool mFlg = false;
for (int i = 0; i < elLinkCol.Count; i++)
{
HtmlElement elLink = elLinkCol[i];
// <link>内のtype属性を確認し、属性値が
// "application/rss+xml"か確認
if (elLink.GetAttribute("type").Equals("application/rss+xml") &&
elLink.GetAttribute("title").Equals("RSS") )
{
// 一致した場合、メッセージボックスでURLを表示
MessageBox.Show(
elLink.GetAttribute("href"),
"RSSのURL取得",
MessageBoxButtons.OK);
mFlg = true;
}
}
if (!mFlg)
{
MessageBox.Show(
"取得できませんでした。",
"RSSのURL取得",
MessageBoxButtons.OK,
MessageBoxIcon.Warning);
}
}
}
}
[補足]
RSSを使用しているホームページのHTMLには、大抵以下のようなRSSに関する情報が追加されている。
<html> <head> : <link type="application/rss+xml" title="RSS" href="http://www.osadasoft.com/rss.xml" /> </head> <body> : </body> </html>
このサンプルでは、<link>タグ内のtype属性の値が”application/rss+xml”のものを探し、href属性の値を取得している。
本当は、GetElementByIdを使って属性値を直接探そうとしたけど、何故かnullしか返らず断念。
問題解決できるなら、GetElementByIdを使った方が良さそう。
あと、HTMLを解析する際、必ずHTMLの読み込み完了を待ってからでないと、HtmlDocumentがnullとなってしまう。
読み込み完了を待ってから(WebBrowserのIsBusyで確認)解析する必要があります。
更に、アプリケーションのイベントもきちんと待たないとダメっぽいです(DoEvents)。
で、更に、Webサイトによっては読み込みに時間がかかるせいか、少し待ってから(Sleep)でないと失敗する場合があります。
このサンプルでは、こんな意外な落とし穴を避けながら作成しています。