RPAツール「UiPath」試用の第三弾。
例えば、自動化で画像や、Webページ、PDFなどから文字列を読み取って、テキストとしてExcelに貼り付けるような自動化をしたい場合、まずは画像認識が必要となるので今回はそこを挑戦。
で、結論から言うと、素のUiPathでは英語しか読み取れない。
ので、日本語を読み取れるようにする必要がある。
なので、そこの手順も追記しています。
手順:
- UiPath Studioを起動
- 「Weblome to UiPath Studio」のダイアログが出たら「Continue Free」を選択。
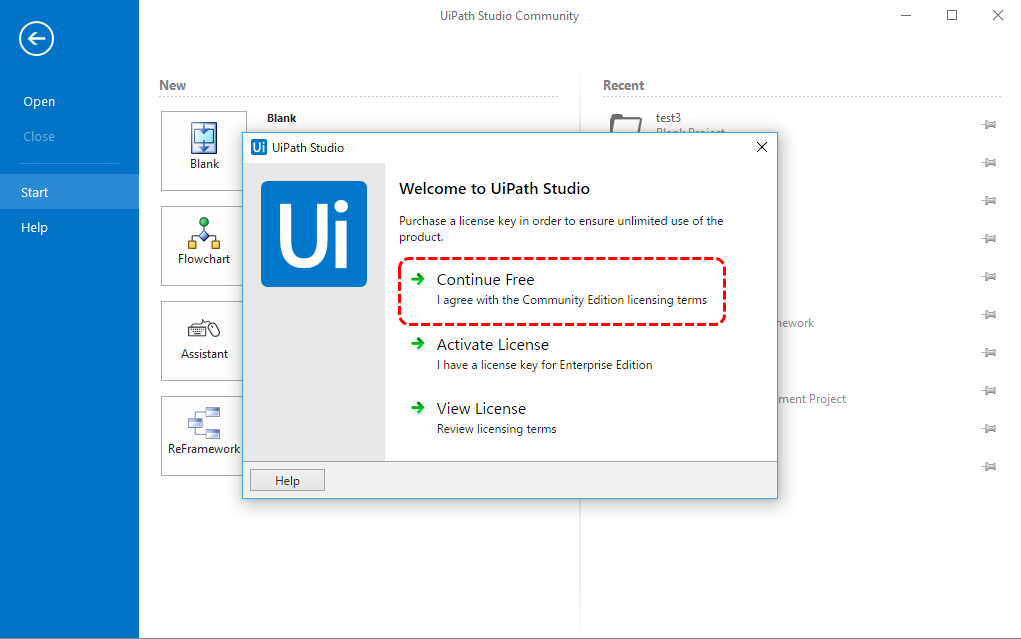
ライセンス未登録の場合は、このようなダイアログが出てくる。
しばらく「Community Edition」で試用ということで上記を選択。
- 「Blank」を選択。
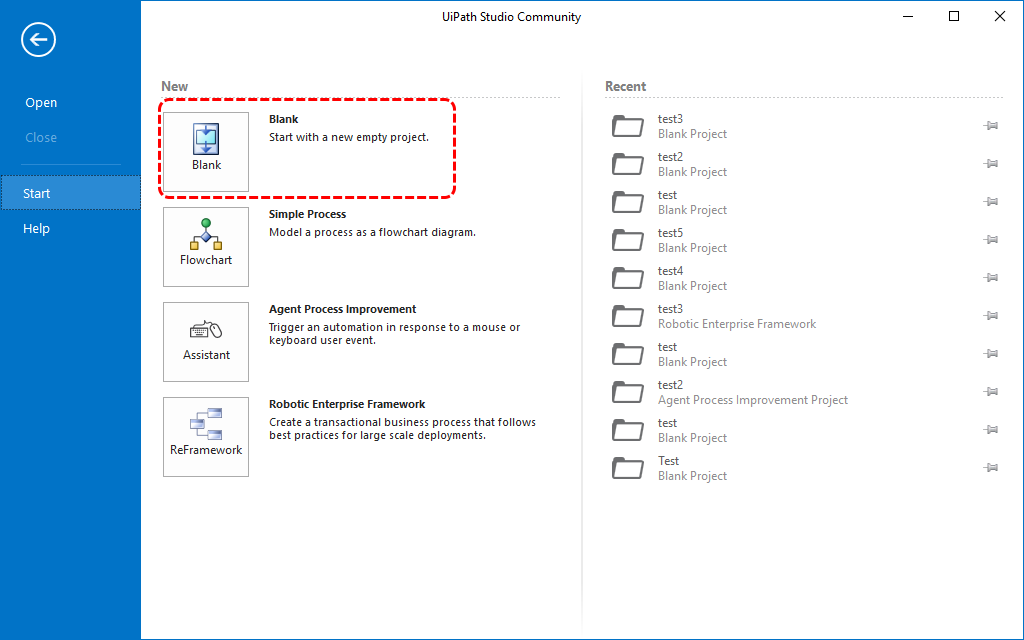
空プロジェクトから作成する。
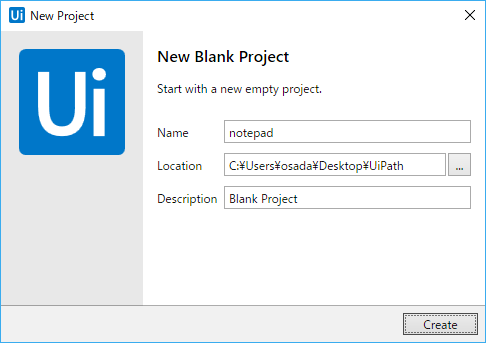
- 「New Blank Project」ダイアログで適当なNameを指定し[Create]ボタン押下。
- UiPath Studioの画面が表示される。
- UiPath Studioの画面が表示される。
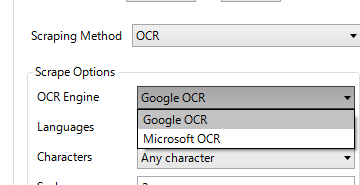
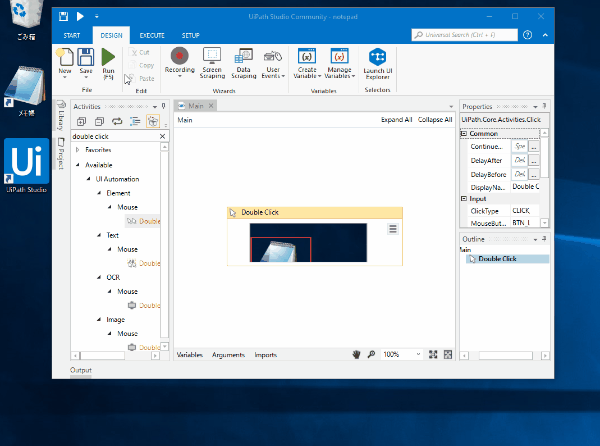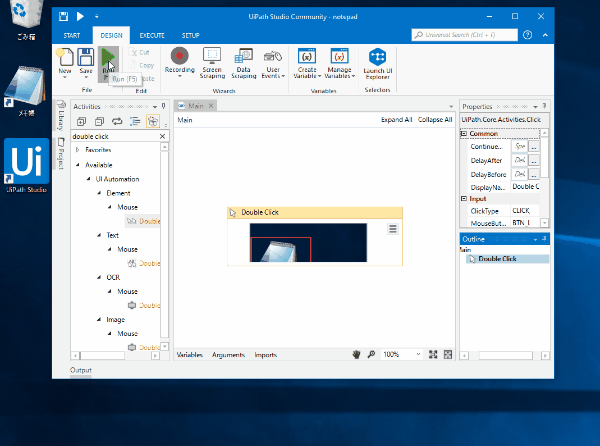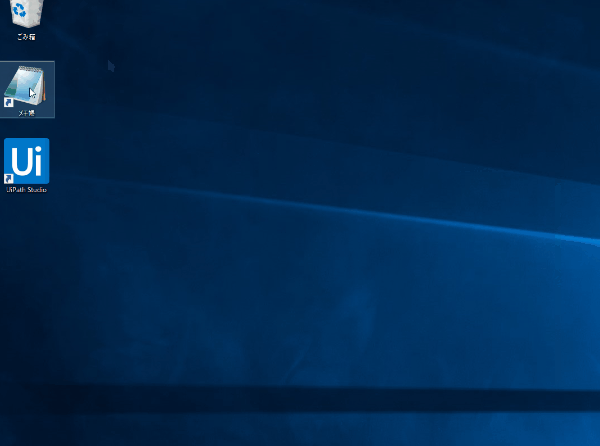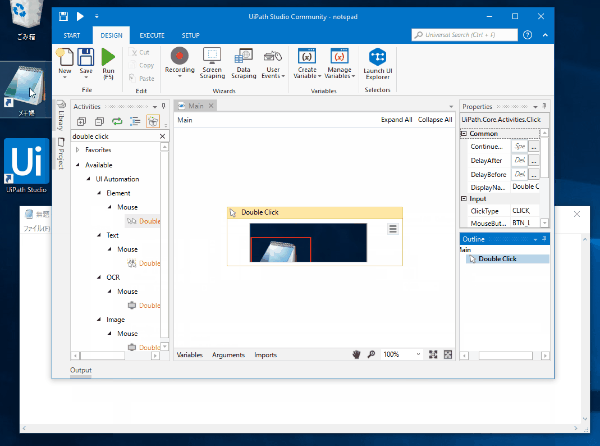
文字認識にはOCRを使うため、左側のアクティビティの検索ボックスに「ocr」と入力する。
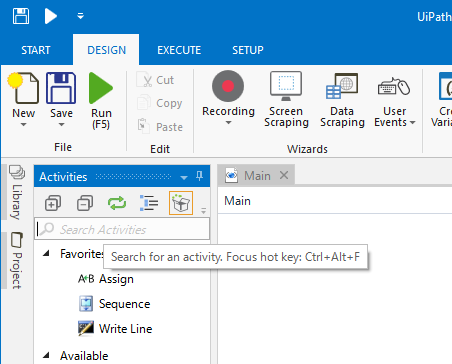
- アクティビティのツリーに検索結果が表示されるので、その中の、「Avaliable>Ui Automation>OCR>Screen Scraping>Get OCR Text」を右側のペイン(Mainタブ)にドラッグする。
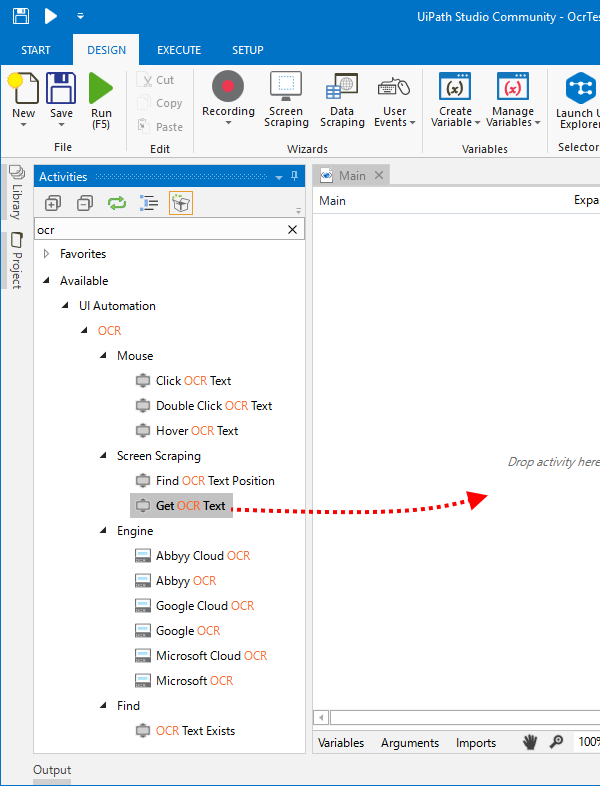
すると、↓こんな感じで「Get OCR Text」のアクティビティがMainのフローに追加される。
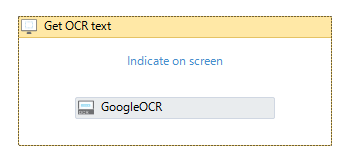
- 画面の文字列を認識させるため、「Get OCR Text」アクティビティ内の「Indicate on screen」をクリック。
すると、UiPath Studioが消えるので、読み取りたい範囲を選択する。
試しに、ファイルのプロパティ画面の文字列を読み込んでみる。
(今回は文字列読み取りがメインのため、予め画面を表示しておいて上記を実行)
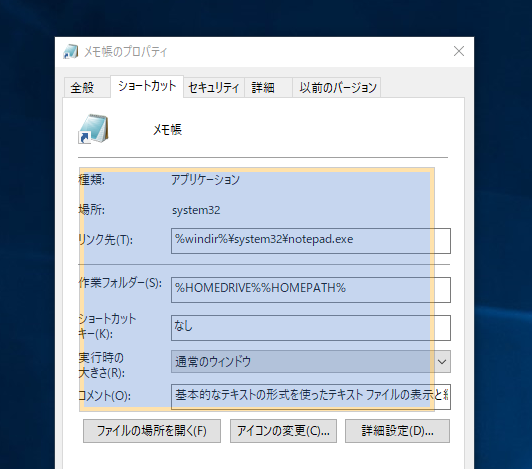
すると、UiPath Studioに対象の画像が表示される。
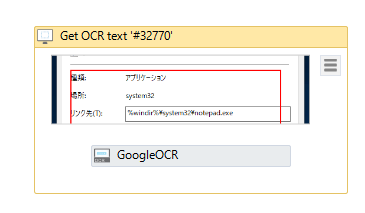
- 読み込んだ情報は変数に格納する必要があるので、画面下側にある「Arguments」タブを選択し、適当な変数名”infomation”を入力。
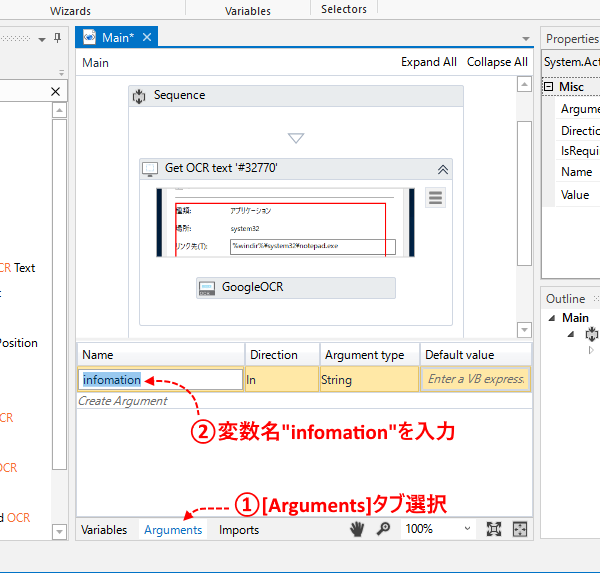
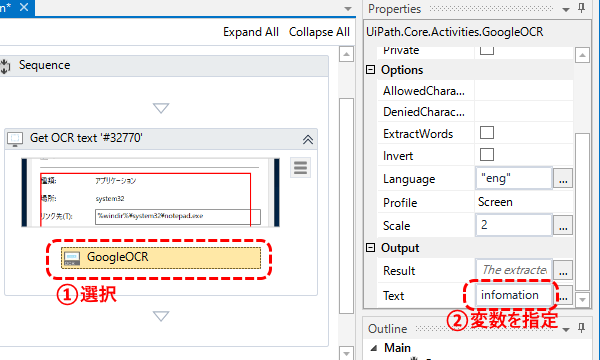
- “GoogleOCR”を選択し、Textプロパティに、先ほど作成した”infomation”変数を指定する。
これで、Google OCRで読み取った文字が、変数に格納されることになる。
- 読み取った結果をメッセージボックスで表示するため、ツリーで”Message box”アクティビティを検索し、フローに追加する。
更に、先ほどの変数infomationを指定する。
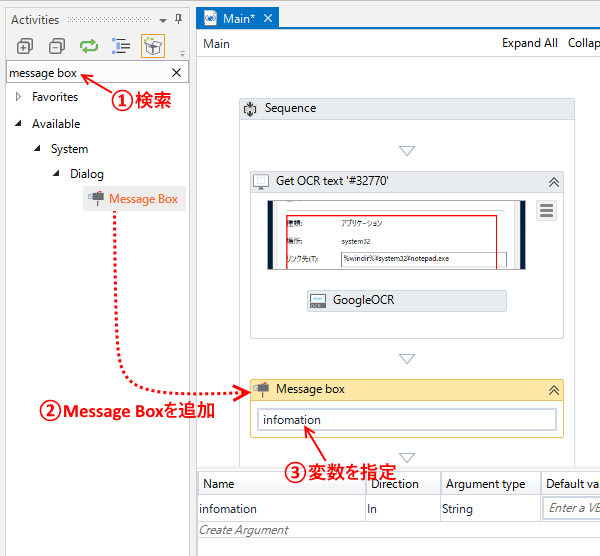
これで、定義完了。
- [Run]ボタンをクリックし実行。
![[Run]ボタンをクリック](https://www.osadasoft.com/wp-content/uploads/2018/09/11-1.gif)
完成。
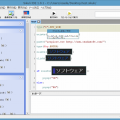
と思いきや、文字認識した結果のメッセージボックスを見てみると、↓文字化けしている。
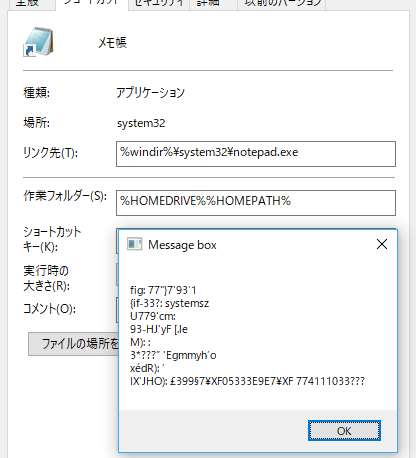
- 日本語を使用するためには、日本語OCRを有効にする必要があるらしい。
以下、日本語対応のざっくりとした手順。
- とりあえず、[Save]ボタンで保存。
- 一旦、UiPath Studioを終了。
- 日本語OCRをGitHubからダウンロード。
https://github.com/tesseract-ocr/tessdata/blob/4.00/jpn.traineddata
- ダウンロードした”jpn.traineddata”をUiPath Studioのtessdataフォルダにコピー。
例)C:\Users\osada\AppData\Local\UiPath\app-18.2.4\tessdata\jpn.traineddata
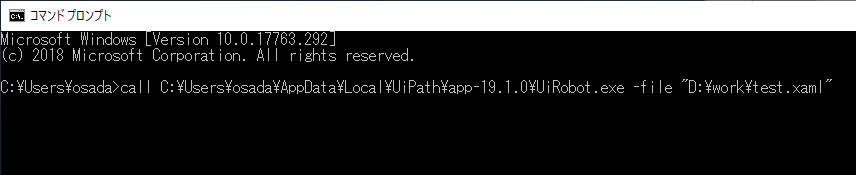
- UiPath Studioを起動し、さっき保存したプロジェクトを開く
- フローの「GoogleOCR」を選択し、Languageプロパティを”eng”から”jpn”に修正する。
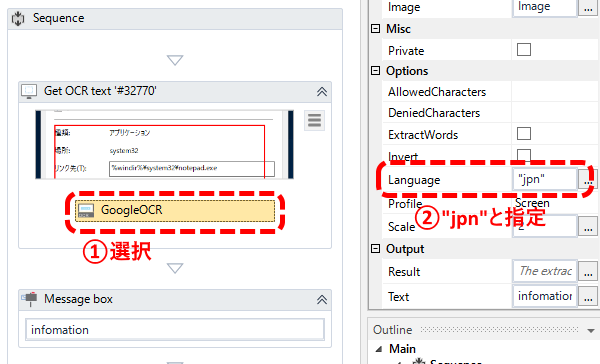
- [Run]ボタンで再実行。
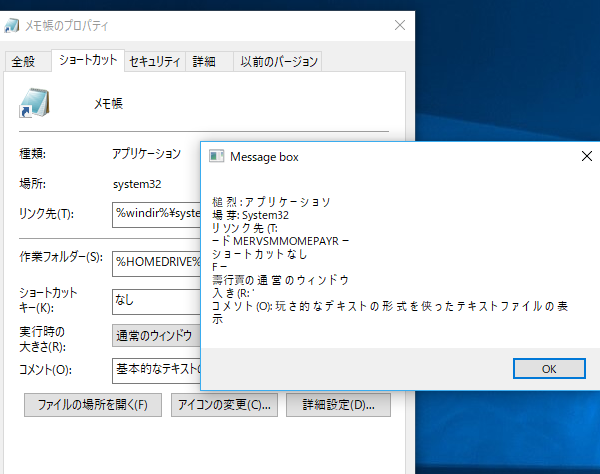
今度は、日本語でそれっぽい結果が表示された。
※日本語対応で参考にさせていただいたサイト。
UiPathの日本語OCR(Googleエンジン)を有効にしよう!
- とりあえず、[Save]ボタンで保存。
OCRによる文字認識なので、コピペのような完璧な文字列が返される訳ではない。
けど、個人的にはこの精度でも充分凄いなぁと感心する。業務では使えないかも知れないけど。
今後もバージョンアップしていけばもっと良くなると思う。
あと、GoogleのOCRだけではなくMicrosoftのOCRも使えるみたい。